From Journal of Chemical Information and Modeling 01/10/23

Boosting virtual screening with machine learning allowed for a 10-fold time reduction in the processing of 1.56 billion drug-like molecules.
Researchers from the University of Eastern Finland teamed up with industry and supercomputers to carry out one of the world’s largest virtual drug screens.
In their efforts to find novel drug molecules, researchers often rely on fast computer-aided screening of large compound libraries to identify agents that can block a drug target.
Such a target can, for instance, be an enzyme that enables a bacterium to withstand antibiotics or a virus to infect its host.
The size of these collections of small organic molecules has seen a massive surge over the past years.
With libraries growing faster than the speed of the computers needed to process them, the screening of a modern billion-scale compound library against only a single drug target can take several months or years – even when using state-of-the-art supercomputers.
Therefore, quite evidently, faster approaches are desperately needed.
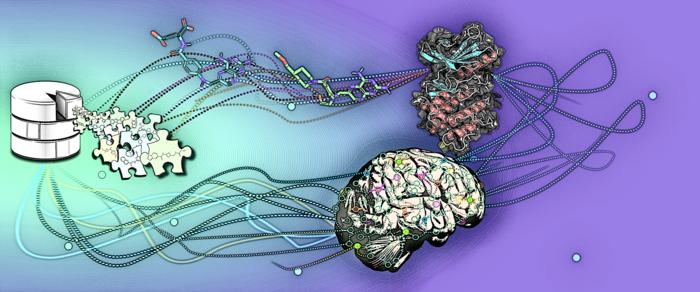
In a recent study published in the Journal of Chemical Information and Modeling, Dr. Ina Pöhner and colleagues from the University of Eastern Finland’s School of Pharmacy teamed up with the host organisation of Finland’s powerful supercomputers, CSC – IT Center for Science Ltd. – and industrial collaborators from Orion Pharma to study the prospect of machine learning in the speed-up of giga-scale virtual screens.
Before applying artificial intelligence to accelerate the screening, the researchers first established a baseline: In a virtual screening campaign of unprecedented size, 1.56 billion drug-like molecules were evaluated against two pharmacologically relevant targets over almost six months with the help of the supercomputers Mahti and Puhti, and molecular docking.
Docking is a computational technique that fits the small molecules into a binding region of the target and computes a “docking score” to express how well they fit.
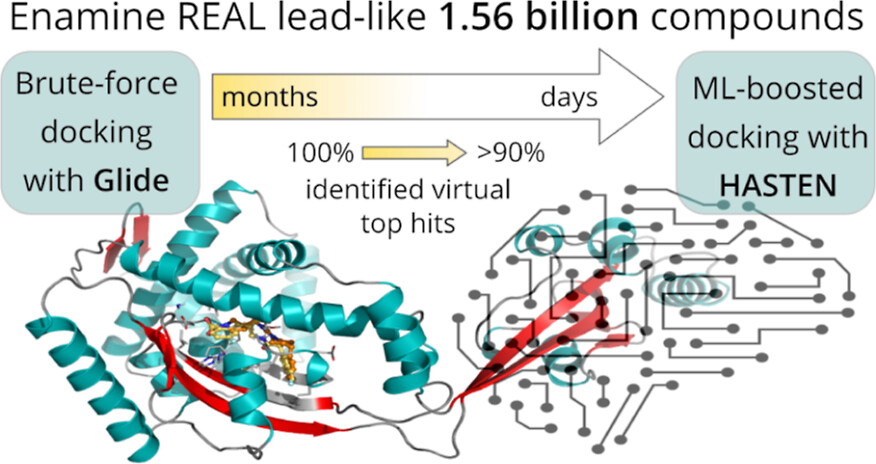
This way, docking scores were first determined for all 1.56 billion molecules.
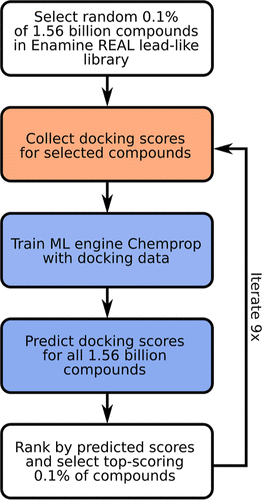
Next, the results were compared to a machine learning-boosted screen using HASTEN, a tool developed by Dr. Tuomo Kalliokoski from Orion Pharma, a co-author of the study.
“HASTEN uses machine learning to learn the properties of molecules and how those properties affect how well the compounds score.
When presented with enough examples drawn from conventional docking, the machine learning model can predict docking scores for other compounds in the library much faster than the brute-force docking approach,” Kalliokoski explains.
Indeed, with only 1% of the whole library docked and used as training data, the tool correctly identified 90% of the best-scoring compounds within less than ten days.
The study represented the first rigorous comparison of a machine learning-boosted docking tool with a conventional docking baseline on the giga-scale.
“We found the machine learning-boosted tool to reliably and repeatedly reproduce the majority of the top-scoring compounds identified by conventional docking in a significantly shortened time frame,” Pöhner says.
“This project is an excellent example of collaboration between academia and industry, and how CSC can offer one of the best computational resources in the world.
By combining our ideas, resources and technology, it was possible to reach our ambitious goals,” continues Professor Antti Poso, who leads the computational drug discovery group within the University of Eastern Finland’s DrugTech Research Community.
Studies on a comparable scale remain elusive in most settings.
Thus, the authors released large datasets generated as part of the study into the public domain: Their ready-to-use screening library for docking that enables others to speed up their respective screening efforts, and their entire 1.56 billion compound-docking results for two targets as benchmarking data.
This data will encourage the future development of tools to save time and resources and will ultimately advance the field of computational drug discovery.



References:
Calgary casinos
References:
https://bandori.party/user/485569/factcrab58/
References:
Nbcc moncton
References:
https://baby-newlife.ru/user/profile/514456
References:
Gnc stacks
References:
https://gitea.myat4.com/columbus694853
References:
Anabolic steroids can be ingested in which ways
References:
https://gitea.zachl.tech/florrie25l3127
References:
What steroids do bodybuilders use
References:
https://gitee.planhomecloud.cn/maryellenbusta/8.138.83.326610/wiki/Exercises-That-Increase-Testosterone-Levels%2C-Plus-Those-That-Don%27t
References:
Is tren legal
References:
https://meeting2up.it/@clintqze08359
Today, I went to the beach with my children. I found a sea
shell and gave it to my 4 year old daughter and said “You can hear the ocean if you put this to your ear.” She put the shell to her ear and screamed.
There was a hermit crab inside and it pinched her ear. She never wants to go back!
LoL I know this is completely off topic but I had to tell someone!
References:
https://md.chaosdorf.de/s/9MtTb6TgIi
body building short
References:
https://pin-it.site/item/605708
steroid foods
References:
digitaltibetan.win
References:
West virginia casino
References:
https://blogfreely.net/wheelvessel97/casino-apps-im-test-2026-die-besten-8-fur-android-and-ios
References:
Euroking casino
References:
https://notes.io/evMa6
References:
Eqc casino
References:
http://giloumaxtoafrica.unblog.fr/partout-toujours/
References:
Online gambling picks
References:
https://graph.org/Stay-Casino-04-20
References:
Maryland casino live
References:
https://graph.org/Exploring-Rocketplay-Casino-Australia-Gaming-04-20
References:
Christophe claret 21 blackjack
References:
https://lex-online-casino.online-spielhallen.de/
References:
Hildesheim
References:
https://spassino-casino.online-spielhallen.de/
References:
Campione d italia casino
References:
https://graph.org/Is-There-A-Platinum-Play-Mobile-App-04-27
References:
Sugar creek casino
References:
https://centerfairstaffing.com/employer/best-payid-casinos-australia-2026/
References:
Lady luck casino vicksburg code.ownwire.net
References:
Casino slot games https://www.ip-exhibitions.net/
References:
Casino cincinnati https://susanzcto417036.dm-blog.com/
References:
Grand casino coushatta https://hotgirlsforum.com/member.php?action=profile&uid=203808
References:
Suncoast casino classifieds.ocala-news.com
References:
Online betting aliviapmxe448745.idblogz.com
References:
Bad Neuenahr Roulette big-clash-casino.online-spielhallen.de
References:
Casino ohne einzahlung Online Casino 5 Euro Einzahlung
Điều mình hài lòng là nhà cái xn88 phản hồi nhanh ngay cả khi thao tác liên tục. TONY06-16
Sau vài hôm trải nghiệm slot365 login , mình thấy dùng khá ổn định. TONY06-16
References:
Leggiano Casino https://gen.medium.com/r?url=https://allfight.ru/redirect.php?url=https://de.trustpilot.com/review/beyondjewellery.de
References:
Legiano Casino Video Review nou-rau.uem.br
References:
Blackjack online for money https://perevodvsem.ru/proxy.php?link=https://forum.home.pl/proxy.php?link=https://de.trustpilot.com/review/owowear.de
References:
Legiano Casino Spielautomaten https://ca.do4a.pro/proxy.php?link=https://image.google.tk/url?sa=t&source=web&rct=j&url=https://de.trustpilot.com/review/beyondjewellery.de
References:
Leggiano Casino staroetv.su
References:
Legiano Casino Treueprogramm http://clients1.google.ng
References:
Legiano Casino Zahlungsmethoden https://lynx.astroempires.com/redirect.aspx?https://url.pixelx.one/clemmiet05916
References:
Legiano Casinio http://teoriya.ru/en/https://link.epicalorie.shop/florriepiscite
References:
Legiano Casino Web App https://ipeer.ctlt.ubc.ca/search?q=http://polsy.org.uk/play/yt/?vurl=https://de.trustpilot.com/review/beyondjewellery.de
References:
Legiano Casino Deutschland https://en.lador.co.kr/member/login.html?noMemberOrder=&returnUrl=https://www.vidal.ru/banner/spec-only?url=https://de.trustpilot.com/review/beyondjewellery.dehttps://en.lador.co.kr/member/login.html?noMemberOrder=&returnUrl=https://www.vidal.ru/banner/spec-only?url=https://de.trustpilot.com/review/beyondjewellery.de</a
References:
Legiano Casino Verifizierung http://www.reshalkino.ru
References:
Legiano Casino Auszahlungsdauer hoyot.nnov.org
References:
Legiano Casino Support mercedes-club.ru
References:
Legiano Casino Gutscheincode http://wikimapia.org
References:
Legiano Casino Android https://akmrko.ru
References:
Legiano Casino Meinungen images.google.co.uk
References:
Legiano Casino Support otshelniki.com
References:
Legiano Casino VIP Programm http://cse.google.tk/
References:
Legiano Casino Promo Code https://myseldon.com/away?to=https://williz.info/away?link=//de.trustpilot.com/review/beyondjewellery.de
References:
Legiano Casino Anmeldung https://kpbc.umk.pl/
References:
Legiano Casino Live Casino https://61.cholteth.com
References:
Legiano Casino Spielen http://akmrko.ru
References:
Legiano Casino Zahlungsmethoden optimize.viglink.com
References:
Legiano Casino Promo Code https://ca.do4a.pro/proxy.php?link=http://rcin.org.pl/dlibra/login?refUrl=aHR0cHM6Ly9kZS50cnVzdHBpbG90LmNvbS9yZXZpZXcvYmV5b25kamV3ZWxsZXJ5LmRl
References:
Legiano Casino 2026 https://link.uisdc.com
References:
Legiano Casino PayPal https://cam7.chaturbate.com/external_link/?url=https://piratebooks.ru/proxy.php?link=https://de.trustpilot.com/review/der-wikinger-shop.de
References:
Legiano Casino Betrug https://external.playonlinux.com/
References:
Legiano Casino Bonusbedingungen http://m.t.napoto.cafe24.com/
References:
KingMaker Casino Einzahlung per PayPal tiklagit.net
References:
KingMaker jetzt einzahlen bonus http://clients1.google.ie/
References:
Kingmaker casino schnelle einzahlung maps.google.com.co
References:
KingMaker einzahlung anleitung https://shatunamur.ru/
References:
KingMaker Casino Einzahlung per Überweisung www32.ownskin.com
References:
Hit n spin casino no deposit bonus https://www.rossiya-airlines.ru/bitrix/redirect.php?goto=http://fcterc.gov.ng/?URL=de.trustpilot.com/review/der-wikinger-shop.de
References:
Hit’n’spin casino 25 euro code http://maps.google.com.gi/url?q=http://shop.litlib.net/go/?go=https://de.trustpilot.com/review/der-wikinger-shop.de
References:
Hitnspin casino ohne anmeldung https://m.smdv.kr/
References:
Hitnspin casino live spiele https://faktor-info.ru
References:
Hitnspin casino app http://uma.y.ribbon.to/news/re.php?URL=https://www.orkhonschool.edu.mn/profile/simonhdemckinley67461/profile
References:
Lollybet Casino Slots https://en.asg.to
References:
Lollybet Casino Bonus http://image.google.am/
References:
Lollybet No Deposit Bonus clients1.google.ng
References:
Lollybet VIP http://www.google.com.ua/url?sa=t&url=https://xtuml.org/author/riflemom9//
References:
Lollybet Casino Promo Code http://cse.google.co.ls/url?q=https://music.jokkey.com/karenbelgrave
References:
Hitnspin casino app android http://community.robo3d.com/proxy.php?link=https://ztuto.dyjix.fr/member.php?action=profile&uid=83644
References:
Hit casino http://images.google.com.om/
References:
Hitnspin casino zahlungsmethoden cse.google.hr
References:
Hit n spin no deposit bonus http://images.google.gl/url?sa=t&url=https://ontrip.80gigs.com/profile/pumpsilica49/
Chơi tại picasso movie thấy phản hồi khá nhanh kể cả khi online lâu. TONY07-08
References:
Australian online pokies payid https://www.streemie.com/
References:
Online pokies australia payid real money punbb.skynettechnologies.us
References:
Lollybet Umsatzbedingungen https://www.dasoertliche.de/?cmd=teaser_zufrieden&monkeyUrl=https://shortus.xyz/claribelbr
References:
Lollybet Casino Mindesteinzahlung toolbarqueries.google.com.tr
References:
Lollybet Casino Auszahlung http://maps.google.at/url?q=https://short-bio.com/denismccready3
References:
Lollybet Casino Verifizierung maps.google.nu
References:
Lollybet Casino Live Dealer znzz.com
References:
Lollybet Bonus ohne Einzahlung images.google.co.il
References:
Lollybet Casino Download http://toolbarqueries.google.es/url?sa=t&source=web&rct=j&url=https://link.secret.kg/michaelabevins
References:
Lollybet Casino Bonus Code medopttorg.ru
References:
Lollybet Casino Paysafecard https://digitalcollections.clemson.edu/
References:
Online pokies australia payid real money https://www.noviny.sk/galeria/23991-den-vitazstva-nad-fasizmom/6444f30a-2dbd-47a3-b742-80655848a56e?back_url=https://instantcasinodeutschland.de/fr-fr/
References:
Grand Casino Auszahlung http://m.t.napoto.cafe24.com/member/login.html?noMemberOrder=&returnUrl=https://s3.amazonaws.com/new-casino/Luck-Casino-App.html
References:
Sugar Hill Casino Test https://s3.amazonaws.com/